==当集群中只有一个节点的时候,将导致整个集群不可用。==
集群职责划分 elasticsearch中集群节点有不同的职责划分:
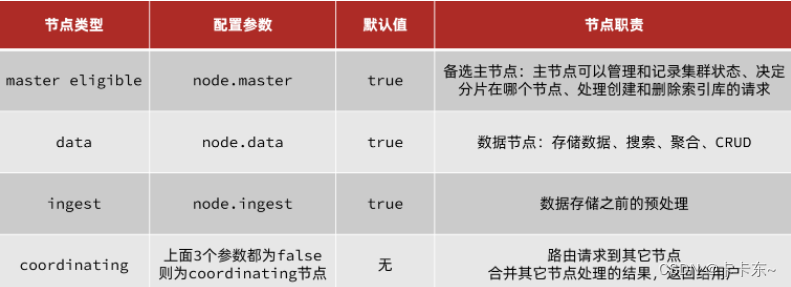
默认情况下,集群中的任何一个节点都同时具备上述四种角色。
但是真实的集群一定要将集群职责分离:
master节点:对CPU要求高,但是内存要求第
data节点:对CPU和内存要求都高
coordinating节点:对网络带宽、CPU要求高 职责分离可以让我们根据不同节点的需求分配不同的硬件去部署。而且避免业务之间的互相干扰。
一个典型的es集群职责划分如图:
ES写入流程
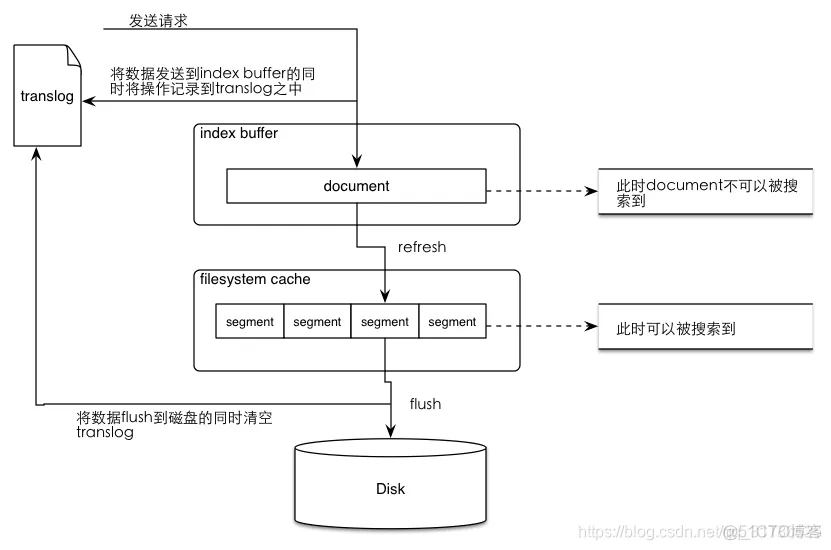
集群路由
文档路由 document路由到shard分片上,就叫做文档路由 ,如何路由? 路由算法 算法公式:shard = hash(routing)%number_of_primary_shards 例子: 一个索引index ,有3个primary shard : p0,p1,p2 增删改查 一个document文档时候,都会传递一个参数 routing number, 默认就是document文档 _id,(也可以手动指定) Routing = _id,假设: _id = 1 算法: Hash(1) = 21 % 3 = 0 表示 请求被 路由到 p0分片上面。 自定义路由 请求: PUT /index/item/id?routing = _id (默认) PUT /index/item/id?routing = user_id(自定义路由)---- 指定把某些值固定路由到某个分片上面。 primary shard不可变原因 即使加服务器也不能改变主分片的数量
根据业务场景确定分片和副本
根据节点数配置
在2个节点的情况下
默认即可,即1个主分片,1个副本分片
在3个节点的情况下
重要数据:1个主分片,2个副本分片
不重要的数据:1个主分片,1个副本分片
根据场景设置
- 日志收集:1个副本3个分片
- 搜索功能:2副本3分片
日志收集需要的是写,所以分片数越多越好
搜索功能提供的是读,所以副本数越多效果越好
# 创建test索引
PUT /test/
{
"settings":{
"number_of_shards": 2,
"number_of_replicas": 1
}
}
# 更改索引test分片副本数量,主分片数number_of_shards创建索引的时候确定好后不能再修改
PUT /test/_settings
{
"settings":{
"number_of_replicas": 1
}
}更改分片副本数量
curl -X PUT "localhost:9200/my_index/_settings" -H 'Content-Type: application/json' -d'
{
"index": {
"number_of_replicas": 1
}
}'节点数、分片数、副本数关系公式:
Max number of nodes = Number of shards * (number of replicas +1)
换句话说,如果你计划用10个分片和2个分片副本,那么最大的节点数是30。
集群规格和容量规划
当您准备创建 Elasticsearch 实例时,建议提前评估集群所需的资源。一般情况下需要评估所需磁盘容量、集群规格、存储的文件类型、大小和数量等。基于这些资源评估,预先规划合适的 Elasticsearch 集群配置,可以减少后续使用过程中的问题和风险。
重要知识: ES 集群的物理磁盘容量 不等于 ES 集群可使用数据空间大小
要进行 Elasticsearch 的容量规划,需要考虑以下因素:
- 使用场景:主要使用的业务场景,不同场景下产生的数据量不同
- 文档数量:确定要存储的文档数量,以及每个文档的大小
- 存储需求:确定所需的存储空间,以便存储所有文档以及任何相关数据
- 索引需求:选择适当的索引策略和设置以确保性能和可扩展性
- 查询需求:确定查询负载的复杂性和大小,以便为其分配足够的资源
- 集群规模:确定集群的大小和数量,以便支持预期的负载并提供高可用性和容错性
基础要求规划
在存储容量规划的开始时,需要预先确认两个 使用场景 和 数据要求 规划:
- 使用场景
- 日志场景
- 搜索场景
- 数据分析场景
- 数据库加速场景
- 通用场景
- 数据要求
- 源数据大小或者预估文档条数和单个文档的大小
- 每日数据增量情况
- 数据保留时长
- 需要的副本数
ES磁盘容量预估
Elasticsearch 中除了数据之外,还有其他的开销,这些也是影响 Elasticsearch 服务存储容量的主要原因,如:
- 索引开销:可以使用 cat/indices?v API 和 _pri.store.size 值计算确切的开销计算,通常比源数据大 10%( _all 参数等未计算)
- 操作系统预留空间:默认操作系统会保留5%的文件系统供您处理关键流程、系统恢复以及防止磁盘碎片化问题等
- Elasticsearch 内部开销:段合并、日志等内部操作,一般预留 20%
- 副本数量: 副本有利于增加数据的可靠性,但同时会增加存储成本
- 安全阈值: 为了预防突发的数据增长,请大致保留 15% 的容量空间作为安全阈值
所以,为了数据的安全和稳定,我们建议您的磁盘使用率不要超过 85% ;或者在即将达到 85%,应该尽快扩充升级。
快速计算公式
| 完整公式 | 简化版本 |
|---|---|
| 源数据 * (1 + 副本数量) * ( 1 + 索引开销) / (1 - Linux 预留空间) / (1 - 内部开销) = 最小存储要求 | 源数据 * (1 + 副本数量)* 1.45 = 最小存储要求 |
| ES建议存储容量 = 源数据 * (1 + 副本数量) * 1.45 * (1 + 预留空间) ≈ 源数据 * (1 + 副本数量) * 2.2 |
==如果有 500G 数据存储并且需要一个副本,则最低存储要求更接近 500 * 2 * 1.1 / 0.95 / 0.8 = 1.5T==
关于节点磁盘的配置
使用场景不同,单节点最大承载数据量也会不同,具体如下:
- 数据加速、查询聚合等场景:单节点磁盘最大容量 = 单节点内存大小(GB)* 10
- 日志写入、离线分析等场景:单节点磁盘最大容量 = 单节点内存大小(GB)* 50
- 通用场景:单节点磁盘最大容量 = 单节点内存大小(GB)* 30
ES 集群实例配置推荐
在生产环境部署推荐配置:尽量一个节点只承担一个角色。不同节点所需要的计算资源不一样。不同角色分离后,可以按需扩展互不影响。
- 集群最大节点数 = 单节点 CPU * 5
- 单节点磁盘最大容量
- 搜索类场景:单节点磁盘最大容量 = 单节点内存大小(GB)* 10。
- 日志类等场景:单节点磁盘最大容量 = 单节点内存大小(GB)* 50。
| 配置 | 最大节点数 | 单节点磁盘最大容量 (查询) | 单节点磁盘最大容量 (日志) |
|---|---|---|---|
| 4 核 16G | 20 | 160 GB | 800 GB |
| 8 核 32G | 40 | 320 GB | 1.5 TB |
| 16 核 64G | 80 | 640 GB | 2 TB |
分片数量规划
适用场景:
- 日志类,写入频繁,查询较少,单个分片 30G 左右
- 搜索类,写入少,查询频繁,单个分片不超过 20G
每个 Elasticsearch 索引被分为多个分片,数据按哈希算法打散到不同的分片中。由于索引分片的数量影响读写性能和故障恢复速度,建议提前规划。
分片使用概要
- Elasticsearch 在 7.x 版本中,每个索引默认为 1 个主分片 和 1 个副本分片
- 在单节点上,7.x 版本最大分片数量为 1000
- 单个分片大小尽量保持在 10-50G 之间为最佳体验,一般推荐在 30G 左右
- 分片过大可能使 Elasticsearch 的故障恢复速度变慢
- 分片过小可能导致非常多的分片,因为每个分片会使用占用一些 CPU 和内存,从而导致读写性能和内存不足的问题。
- 当分片数量超过数据节点数量时,建议分片数量接近数据节点的整数倍,便于将分片均匀的分布到数据节点中。
- 对日志场景,建议启用 ILM 功能。在发现分片大小不合理时,通过该功能及时调整分片数量。
分片计算公式
(元数据 + 增长空间) * (1 + 索引开销) / 所需的分片大小 = 主分片的大约数量
假设有 80GiB 的数据。希望将每个分片保持在 30GiB 左右。因此,您的分片数量应大约为 80 * 1.1 / 30 = 3
分片设置的可参考原则:
ElasticSearch推荐的最大JVM堆空间是30~32G, 所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估算. 例如, 你认为你的数据能达到200GB, 推荐你最多分配7到8个分片。 在开始阶段, 一个好的方案是根据你的节点数量==按照1.5~3倍的原则==来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3x3)个。当性能下降时,增加节点,ES会平衡分片的放置。 对于基于日期的索引需求, 并且对索引数据的搜索场景非常少. 也许这些索引量将达到成百上千, 但每个索引的数据量只有1GB甚至更小. 对于这种类似场景, 建议只需要为索引分配1个分片。如日志管理就是一个日期的索引需求,日期索引会很多,但每个索引存放的日志数据量就很少。
副本设置基本原则:
为保证高可用,副本数设置为2即可。要求集群至少要有3个节点,来分开存放主分片、副本。 如发现并发量大时,查询性能会下降,可增加副本数,来提升并发查询能力。
注意:新增副本时主节点会自动协调,然后拷贝数据到新增的副本节点
如何避免脑裂问题?
3.1 脑裂问题:
一个集群中只有一个A主节点,A主节点因为需要处理的东西太多或者网络过于繁忙,从而导致其他从节点ping不通A主节点,这样其他从节点就会认为A主节点不可用了,就会重新选出一个新的主节点B。过了一会A主节点恢复正常了,这样就出现了两个主节点,导致一部分数据来源于A主节点,另外一部分数据来源于B主节点,出现数据不一致问题,这就是脑裂。
3.2 尽量避免脑裂,需要添加最小数量的主节点配置:
discovery.zen.minimum_master_nodes: (有master资格节点数/2) + 1
这个参数控制的是,选举主节点时需要看到最少多少个具有master资格的活节点,才能进行选举。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。